Chapitre 6 Programmation et calcul
Les problèmes inhérents au calcul et aux codes associés partagent des similarités avec les difficultés liées aux données, par exemple la non disponibilité. Toutefois, les questions de calcul ont leurs spécificités du fait de leurs natures opératoires : il s’agit d’exécuter ce code afin d’obtenir un résultat. Or, c’est lors de cette étape d’exécution que vont surgir un certain nombre de complications que l’on peut classer en deux grandes catégories :
- d’une part, celles qui empêchent d’obtenir un résultat
- d’autre part, celles qui rendent un résultat différent voire faux.
Si le premier type de problème est ennuyeux (euphémisme), le second type de problème est d’autant plus grave qu’il est difficile à détecter (effroi intense).
6.1 Le code n’est pas disponible
En guise de préambule, débutons par une liste non exhaustive des cas où l’on n’a tout simplement pas ou plus accès au programme à exécuter :
Les logiciels propriétaires ou la loterie de la licence d’exploitation : votre équipe/structure a cessé de payer la licence. Variante : ce logiciel est disponible dans l’université d’un collègue mais pas dans l’établissement où vous travaillez actuellement. Autre variante : vous avez accès au logiciel, mais seul un nombre restreint de personnes peut y accéder en même temps, via un système de jetons. De fait, vous vous retrouvez à devoir attendre un bon moment avant d’y arriver.
Un seul code vous manque et tout est dépeuplé : le code a été développé “en interne”. Il arrive trop souvent qu’à la suite d’un crash disque, d’un vol d’ordinateur portable, du départ du développeur principal, que l’on n’ait simplement plus accès au logiciel. C’est souvent le résultat d’une politique (ou d’une absence de politique) de sauvegarde ou de partage d’informations au sein d’une équipe.
Le numéro que vous avez demandé n’est plus attribué : assez souvent, il s’agit d’un code développé “en externe” (dans une autre équipe de recherche par exemple) que l’on souhaite ré-exécuter, par exemple pour avoir un point de comparaison ou bien pour vérifier si on obtient bien des résultats similaires avec une autre méthode. En général, on cherche alors le code sur le web mais il est assez courant que l’URL indiquée dans l’article ne soit plus accessible car le développeur a depuis quitté l’équipe où il travaillait et que sa page web a été supprimée ou complètement restructurée. Ce problème est connu sous le nom d’URL decay (Spinellis 2003) ou de Link Rot (Wikipedia 2019b).
Cachez ce code que je ne saurais voir : enfin, les auteurs du code peuvent tout simplement ne pas souhaiter le partager, par exemple parce qu’ils jugent qu’il n’est pas montrable en l’état (pas ou peu de commentaires, structure horrible cachant des erreurs) ou encore pour conserver ce qu’ils considèrent comme un avantage compétitif.
Si cette question vous intéresse, vous pouvez lire les travaux de Collberg, Proebsting et Warren : (Collberg and Proebsting 2016) (Collberg, Proebsting, and Warren 2015). Les auteurs étudient les causes d’incapacité à réexécuter du code dans la communauté de recherche Computer Systems, pourtant très au fait des aspects logiciels. Vous y trouverez de nombreux témoignages (assez drôles si c’était sans conséquence !) issus d’une étude de terrain ; vous pourrez notamment lire les excuses les plus couramment utilisées pour justifier une incapacité à donner accès au code derrière une publication. Vous pouvez aussi consulter “Re-run, Repeat, Reproduce, Reuse, Replicate: Transforming Code into Scientific Contributions” (Benureau and Rougier 2017).
6.3 Comment fonctionne ce code ? Lost in translation
Si on n’est plus sûr des paramètres utilisés, on peut vouloir chercher à comprendre d’où vient le problème en inspectant le code … si tant est qu’on ait accès au code source bien sûr. Or, les logiciels propriétaires ou les logiciels disponibles uniquement sous forme binaire rendent toute inspection de ce type impossible. Mais admettons que vous ayez réussi à inspecter les sources et que vous ayez les compétences pour le comprendre (a minima, un langage de programmation que vous connaissez).
Les codes de recherche, développés pour des besoins spécifiques, sont souvent des prototypes et il est rare de prendre le temps de rédiger une documentation “interne” (à destination des développeurs). Et quand bien même il y aurait des commentaires, encore faut-il qu’ils soient compréhensibles donc a minima en anglais. Par ailleurs, ils doivent aussi correspondre à la réalité : quand un code évolue vite, on ne prend pas toujours le temps d’actualiser au fur et à mesure les commentaires et la documentation. Si ces critères ne sont pas réunis, les commentaires risquent davantage de vous induire en erreur que de vous aider.
Un célèbre dicton en informatique dit : “Programs must be written for people to read, and only incidentally for machines to execute.” C’est une citation d’Harold Abelson tirée de son livre Structure and Interpretation of Computer Programs publié en 1979 (Abelson et al. 1996). Commenter, c’est une chose, mais lorsque l’on cherche à comprendre un programme, on se rend vite compte qu’il est indispensable que les noms de variables et de fonctions aient été bien choisis, que le code ait été été bien structuré avec des fonctions au rôle clairement défini, sans quoi le code devient totalement incompréhensible (ce qui est précisemment l’objet du concours “Obfuscated C” (Broukhis, Cooper, and Curt Noll 2019). De même, lorsque qu’il s’agit d’un code conséquent réparti dans de nombreux fichiers, une mauvaise convention de nommage des fichiers ou bien l’usage d’une structure de fichiers absconse empêchent toute tentative de compréhension.
Enfin, même si le code est relativement compréhensible, il est possible que des bugs (des erreurs de programmation) soient à l’origine de vos malheurs mais comment les trouver ?
6.4 Quelle version du code ?
Nul n’est parfait et les bugs sont donc courants, même chez les programmeurs les plus chevronnés. Il se peut que le bug à l’origine de vos problèmes provienne de la version d’un logiciel actuellement installé sur la machine. Pour corriger ce bug, on peut vouloir mettre à jour le logiciel. Mais quelle version a été utilisée dans le passé et quelle est la version actuelle ? Et comment savoir si c’est effectivement la cause de la différence observée ? La mise à jour n’introduirait-elle pas de nouveaux bugs ? L’idéal serait peut-être de revenir à une version plus ancienne mais comment faire ? Quelle est la version la plus récente que je puisse utiliser ?
Enfin, cette nouvelle version sera-t-elle toujours compatible avec mon ordinateur ? Et si je repars du code source, arriverai-je à le recompiler ?
6.5 L’environnement de calcul ou le paradigme des poupées russes diaboliques
Plus le langage que vous utilisez est de haut niveau, plus il est probable qu’il dissimule une grande complexité. Même le script le plus anodin dépend en général d’une large hiérarchie de bibliothèques que l’on a du mal à imaginer. À titre d’exemple, lorsqu’en Python vous souhaitez faire un petit graphique, il est courant de charger la bibliothèque matplotlib avec un simple :
import matplotlibOr cette bibliothèque est fournie par un “paquet” qui, sur la machine d’un des auteurs s’appelle, python3-matplotlib. Lorsque nous cherchons à en savoir plus sur ce paquet, voilà ce que nous obtenons :
Package: python3-matplotlib
Version: 2.1.1-2
Depends: python3-dateutil, python-matplotlib-data (>= 2.1.1-2),
python3-pyparsing (>= 1.5.6), python3-six (>= 1.10), python3-tz,
libjs-jquery, libjs-jquery-ui, python3-numpy (>= 1:1.13.1),
python3-numpy-abi9, python3 (<< 3.7), python3 (>= 3.6~),
python3-cycler (>= 0.10.0), python3:any (>= 3.3.2-2~), libc6 (>=
2.14), libfreetype6 (>= 2.2.1), libgcc1 (>= 1:3.0), libpng16-16 (>=
1.6.2-1), libstdc++6 (>= 5.2), zlib1g (>= 1:1.1.4)C’est ici la version 2.1.1-2 qui est présente et, pour l’installer, il a fallu installer les paquets python3-dateutil, python-matplotlib-data, python3-pyparsing, etc. C’est ce qu’on appelle les “dépendances”. Mais ces paquets dépendent eux-mêmes d’autres paquets. La figure 6.1 “Exemple des dépendances de la bibliothèque python matplotlib — obtenu avec debtree” (alerte paracétamol) permet de voir le graphe obtenu lorsque l’on récupère l’ensemble des paquets nécessaires avec leurs dépendances.
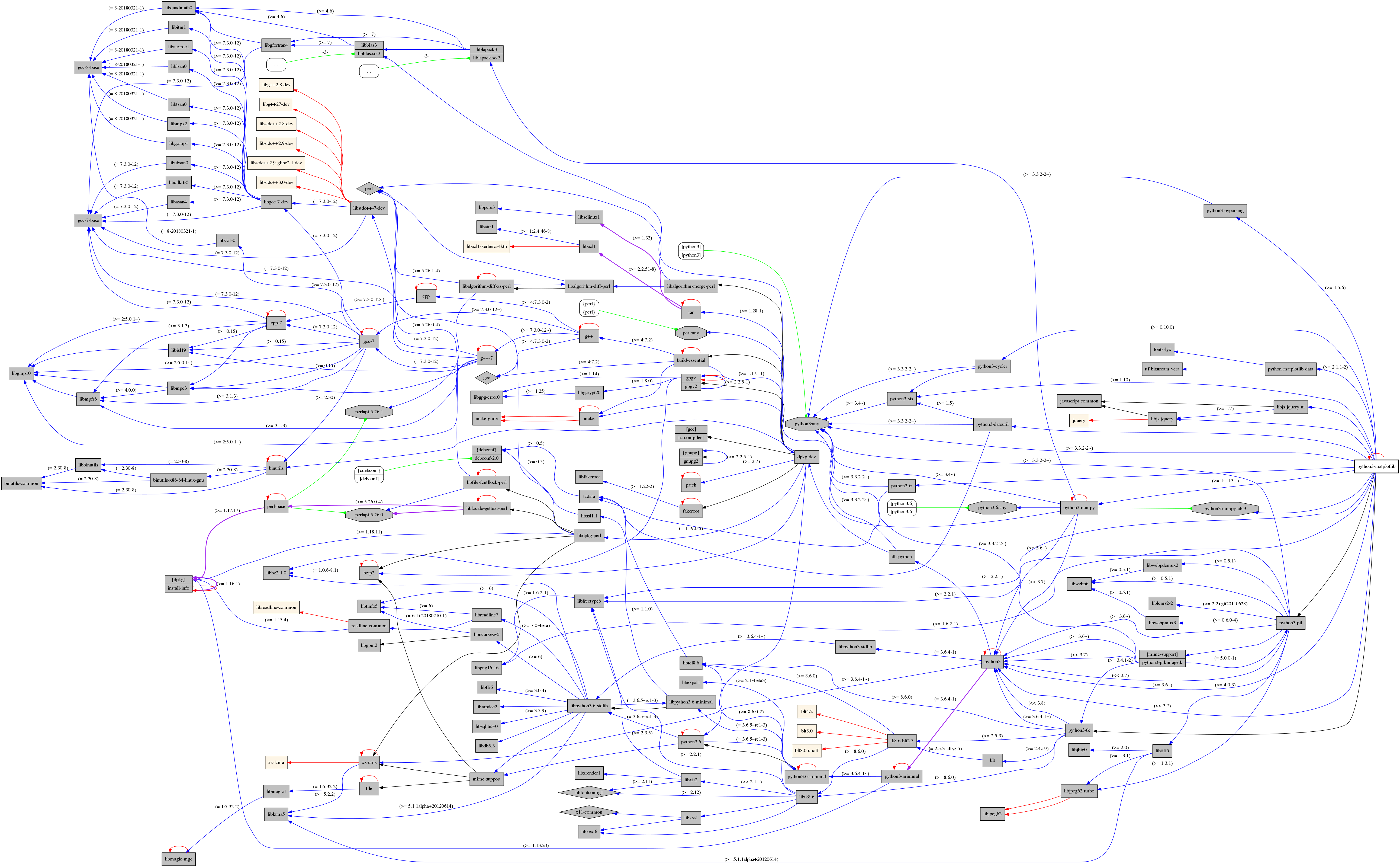
Figure 6.1: Dépendances de Matplotlib sous Debian obtenues avec debtree.
Vous remarquerez dans les dépendances que la version n’est pas précisément indiquée mais qu’il faut par exemple une version supérieure de python3-pyparsing qui soit au moins 1.5.6. Mais si des bugs peuvent être introduits, comment être sûr que votre code fonctionnera de la même façon avec les versions 1.5.6, 1.5.7, etc., sachant que nous en sommes maintenant au moins à la version 2.2.0?
En résumé, tout code, aussi petit soit-il, possède tout un arbre de dépendances qui sont le plus souvent cachées. Ce code s’exécute donc dans un environnement donné et une différence, même insignifiante, de cet environnement peut conduire à des résultats différents, c’est-à-dire à des problèmes de non reproductibilité.
Si vous pensez que ce problème n’est que théorique, nous vous invitons à lire Gronenschild et ses co-auteurs (Gronenschild et al. 2012) qui étudient l’influence de la version de MacOSX et de FreeSurfer, un logiciel permettant de mesurer l’épaisseur corticale et le volume de structures neuroanatomiques.
6.6 Le chaos numérique
Les nombres manipulés par ordinateur ne sont pas des nombres réels, avec une précision infinie, mais des nombres dits “à virgule flottante” qui n’obéissent pas exactement aux mêmes règles que celles que l’on nous enseigne à l’école. Par exemple, si vous demandez à, à peu près n’importe quel ordinateur si 0.1*3==0.3 ou si 3-2.9==0.1 il vous répondra très certainement FALSE (Faux) dans les deux cas. Cela est dû au fait que la représentation au format binaire de ces nombres, en apparence simple, n’est pas exacte. Beaucoup de machines à calculer ont une représentation interne en base 10 un peu différente, or, nous n’avons pas été habitués de manière précoce à intégrer ce genre de problème, sauf peut-être pour des nombres du genre \(1/3\approx 0,3333333\). Lorsque l’on programme, il faut donc faire très attention à cette subtilité qui joue des tours dès que l’on veut comparer deux nombres.
Un autre problème au prime abord surprenant, mais probablement plus simple à comprendre, est la non associativité des opérations. Si avec les nombres réels, il va de soi que \((a+b)+c=a+(b+c)\), ce n’est pas le cas avec les nombres en virgules flottantes. Par exemple, (1e-10+1e10)-1e10 vaut 0 alors que 1e-10+(1e10-1e10) vaut 1e-10. Même une simple moyenne peut donc devenir problématique et, non, il ne suffit pas de trier les nombres avant de les additionner pour résoudre le problème.
Comme vous utilisez vraisemblablement un ordinateur parallèle (même votre téléphone a maintenant plusieurs cœurs de calcul), il est possible que la somme \(a_1 + \dots +a_n\) ne soit pas calculée comme vous l’imaginez (i.e., \((((((((a_1 + a_2) + a_3) + \dots +a_n)\)), mais en plusieurs parties (i.e., \(((((a_1 + a_2) + \dots +a_{n/2}) + ((((a_{n+1} + a_{n+2}) + \dots +a_n)\)), chaque cœur de votre processeur réalisant une des sommes partielles, la somme finale étant faite à la fin. Les résultats peuvent changer par le simple fait de passer d’un ordinateur à un autre alors que les machines semblent avoir le même environnement. Les ordinateurs peuvent ne pas avoir exactement le même nombre de cœurs. Les cœurs d’un ordinateur n’allant pas toujours exactement à la même vitesse, un code un peu optimisé ajustera la taille des sommes partielles pour terminer le calcul le plus rapidement possible et le résultat du calcul variera donc d’une exécution sur l’autre alors que rien n’a changé ! Mais alors, comment décider lequel de ces différents résultats de calculs est le “bon” ?
Toutes ces petites imprécisions de calcul peuvent hélas rapidement devenir très problématiques lorsque le système sous-jacent correspond par exemple à la discrétisation d’une équation différentielle. Le calcul est alors très sensible aux conditions initiales et l’accumulation des imprécisions peut amener à une catastrophe ; voir notamment The Patriot Missile Failure (Arnold 2000).
Il y a de nombreux articles décrivant ce genre de cauchemars :
“Numerical Errors in Minimization Based Binding Energy Calculations” (Feher and Williams 2012b)
“Numerical Errors and Chaotic Behavior in Docking Simulations” (Feher and Williams 2012a)
Vous pouvez vouloir lire le classique What Every Computer Scientist Should Know About Floating-point Arithmetic (Goldberg 1991) ou encore les travaux de Stodden et ses collègues (Stodden and Krafczyk 2018). Pour une présentation de ces problématiques et de quelques solutions, vous pouvez aussi regarder ce séminaire sur la reproductibilité numérique (Legrand 2016a).
Références
Abelson, Harold, Gerald Jay Sussman, Julie Sussman, and Alan J. Perlis. 1996. Structure and Interpretation of Computer Programs. Cambridge, Etats-Unis d’Amérique: MIT Press.
Arnold, Douglas N. 2000. “The Patriot Missile Failure.” Douglas N. Arnold McKnight, Presidential Professor of Mathematics. http://www-users.math.umn.edu/~arnold/disasters/patriot.html.
Benureau, Fabien, and Nicolas Rougier. 2017. “Re-Run, Repeat, Reproduce, Reuse, Replicate: Transforming Code into Scientific Contributions.” arXiv:1708.08205 [Cs], August. http://arxiv.org/abs/1708.08205.
Broukhis, Leo, Simon Cooper, and Landon Curt Noll. 2019. “The International Obfuscated C Code Contest.” The International Obfuscated C Code Contest. http://ioccc.org/.
Collberg, Christian S., and Todd A. Proebsting. 2016. “Repeatability in Computer Systems Research.” Communications of the ACM 59 (3): 62–69. doi:10.1145/2812803.
Collberg, Christian S., Todd A. Proebsting, and Alex M. Warren. 2015. “Repeatability and Benefaction in Computer Systems Research. A Study and a Modest Proposal.” University of Arizona: University of Arizona. http://reproducibility.cs.arizona.edu/v2/RepeatabilityTR.pdf.
Feher, Miklos, and Christopher I. Williams. 2012a. “Numerical Errors and Chaotic Behavior in Docking Simulations.” Journal of Chemical Information and Modeling 52 (3): 724–38. doi:10.1021/ci200598m.
Feher, Miklos, and Christopher I. 2012b. “Numerical Errors in Minimization Based Binding Energy Calculations.” Journal of Chemical Information and Modeling 52 (12): 3200–3212. doi:10.1021/ci300298d.
Goldberg, David. 1991. “What Every Computer Scientist Should Know About Floating-Point Arithmetic.” ACM Comput. Surv. 23 (1): 5–48. doi:10.1145/103162.103163.
Gronenschild, Ed H. B. M., Petra Habets, Heidi I. L. Jacobs, Ron Mengelers, Nico Rozendaal, Jim van Os, and Machteld Marcelis. 2012. “The Effects of FreeSurfer Version, Workstation Type, and Macintosh Operating System Version on Anatomical Volume and Cortical Thickness Measurements.” Edited by Satoru Hayasaka. PLoS ONE 7 (6): e38234. doi:10.1371/journal.pone.0038234.
Legrand, Arnaud. 2016a. “Controling Your Environment.” Series of Webinars and Documents on Reproducible Research. https://github.com/alegrand/RR_webinars/blob/master/2_controling_your_environment/index.org.
Spinellis, Diomidis. 2003. “The Decay and Failures of Web References.” Communications of the ACM 46 (1): 71–77. doi:10.1145/602421.602422.
Stodden, Victoria, and Matthew S Krafczyk. 2018. “Assessing Reproducibility : An Astrophysical Example of Computational Uncertainty in the HPC Context,” August, 5. https://web.stanford.edu/~vcs/papers/ResCuE2018-VSMK.pdf.
Wikipedia. 2019b. “Link Rot.” Wikipedia. https://en.wikipedia.org/w/index.php?title=Link_rot&oldid=893134620.
6.2 Comment lance-t-on ce code ? (“Allô Houston ?”)
Lorsque l’on fait de la recherche, il est courant de devoir développer soi-même un code pour répondre à un besoin spécifique. Que ce soit un “gros” code ou un petit script, on prend rarement le temps de rédiger une documentation “externe” (à destination des utilisateurs) puisque le code est principalement utilisé par les membres de l’équipe que l’on croise tous les jours. Mais lorsque l’on revient quelques mois plus tard, pour ré-exécuter un de ses propres calculs ou bien que l’on essaye de repartir du travail de quelqu’un d’autre (qui a quitté le laboratoire ou n’y a même jamais travaillé), il est courant de ne pas (ou plus) savoir comment il avait été lancé. Avec quels paramètres, quels fichiers d’entrées, quelles variables d’environnement, etc. ? La moindre erreur sur les paramètres conduira à des résultats différents voire à un crash. Et malheureusement pour vous, le “vous” d’il y a 6 mois ne répond pas au mail. Enfin, et comme nous le verrons par la suite, il existe bien d’autres raisons qui peuvent conduire à ces deux symptômes.