Chapitre 16 Environnement logiciel
Attention : ce chapitre traite de sujets appelant des compétences techniques avancées. Nous vous proposons d’aborder la (complexe) question de l’environnement (ça pique mais ça compte).
L’environnement logiciel désigne l’intégralité des logiciels qui assurent la gestion de l’ordinateur et qui sont utilisés pour réaliser la recherche. Les chercheurs peuvent avoir tendance à sous-estimer l’impact de l’environnement logiciel sur leurs résultats. Pour une recherche reproductible, il existe trois enjeux importants autour de l’environnement logiciel :
- identifier et décrire son environnement
- permettre à quelqu’un d’autre d’utiliser un environnement exactement identique
- construire une variation de cet environnement
Il n’existe ni solution simple, ni solution unique pour répondre à ces enjeux. Ce chapitre a pour vocation de fournir une description critique de ces solutions en évoquant notamment leurs limites respectives.
16.1 Identifier les dépendances : dessine-moi une dépendance
La manière la plus simple moins complexe de décrire son environnement logiciel est d’en identifier les dépendances. Mais cette simplicité n’est qu’apparente car l’arbre cache la forêt : chaque dépendance a elle-même une dépendance, qui a elle-même une dépendance, et ainsi de suite… Cette tâche peut donc rapidement devenir difficile. Deux méthodes permettent d’aboutir à une telle identification :
À partir d’un langage interprété (tel que R ou Python), on peut effectuer cette “intro-spection” et lister les différentes dépendances, la liste des bibliothèques chargées avec leur numéro de version. En R, on peut par exemple utiliser la commande
sessionInfo(ou encoredevtools::session_info). Mais cette méthode relativement simple est surtout limitée et assez peu précise car elle ne signale que quelques unes des dépendances système de plus haut niveau. Elle correspond à la zone verte dans le schéma ci-dessous. Cependant, il est très facile d’inclure ces informations descriptives dans vos documents computationnels (cf. chapitre 14 “Rendre son code compréhensible”), et nous vous recommandons cette bonne pratique.En utilisant le gestionnaire de paquets du système d’exploitation, on obtient la liste exhaustive de l’ensemble des applications installées (listant donc des applications non pertinentes pour la recherche ainsi que les doublons de versions successives). Elle correspond à l’ensemble du schéma ci-dessous (donc à TOUT le système d’exploitation).
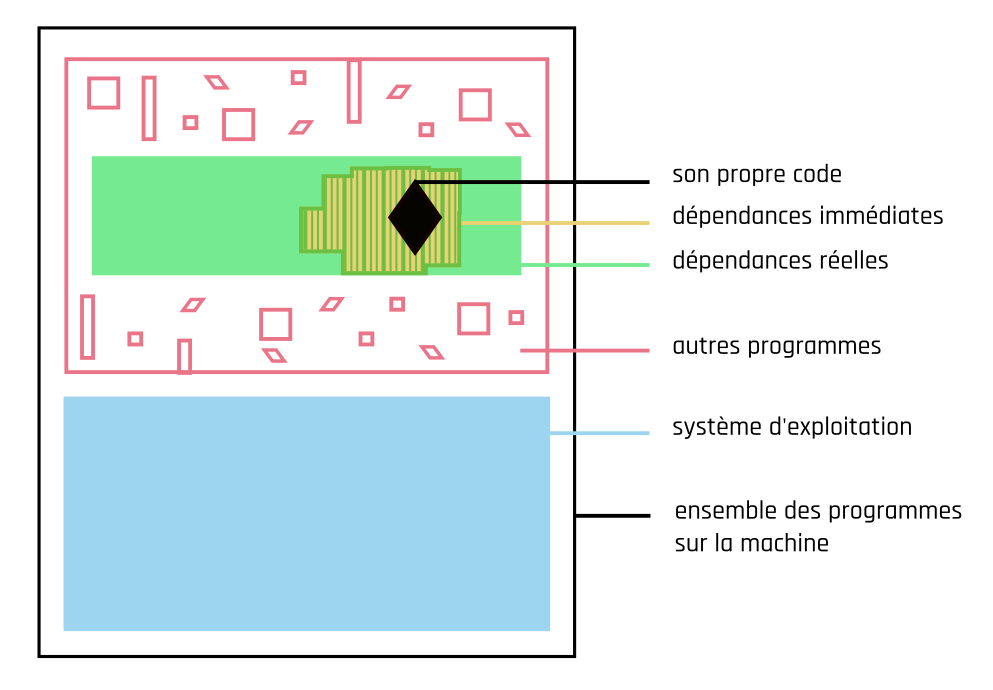
Schéma des différents environnements logiciels
L’identification des dépendances est donc soit lacunaire et imprécise (méthode n°1 ci-dessus), soit au contraire, illisible car trop étendue (méthode n°2 ci-dessus).
Entre ces deux extrêmes, il existe cependant un moyen d’identifier ces dépendances, notamment via des gestionnaires de paquets de langages interprétés tels que Packrat pour R (Lemoine 2017).
Ainsi, permettre à un collègue de travailler avec un environnement logiciel similaire au sien s’avère une tâche ardue. Fournir une description ad hoc ne peut être une opération manuelle tant cette tâche est fastidieuse. De plus, cette description ne résisterait pas à l’absence de standardisation entre systèmes d’exploitation. Il s’agit donc d’une solution informative sur son environnement, mais qui ne permet pas de le reproduire en pratique.
16.2 Préserver le désordre (aka “Preserve the mess”)
L’identification des dépendances permet de décrire son environnement, mais ne permet que très difficilement de le conserver ou le partager en pratique. Une façon de s’assurer de pouvoir conserver et partager un environnement logiciel à l’identique est de “figer” l’ensemble du système.
16.2.1 Isoler une machine
La façon la plus simple d’éviter les problèmes de versions des dépendances logicielles, consiste à installer sur une machine tous les programmes dont on a besoin. Ce scenario exclut toute mise à jour : l’environnement est installé une bonne fois pour toutes.
C’est le cas de figure décrit en section 2.5. Chacun des membres de l’équipe peut alors se connecter sur cette machine pour y faire ses calculs, ce qui peut d’ailleurs parfois être source de tensions : or, personne ne souhaite découvrir à cette occasion les talents en free fight de ses collègues. Sur le long terme, isoler une machine s’avèrera problématique car si la machine continue (normalement) de calculer la même chose, elle conserve ses vieux bugs qui peuvent affecter vos résultats. D’autre part, elle finira un jour par mourir de sa belle mort et s’exposera entre-temps à des failles de sécurité. C’est donc certainement la solution la plus simple à mettre en œuvre (au début), mais c’est une solution à éviter autant que possible.
16.2.2 Isoler un environnement à l’aide d’un conteneur
Un conteneur est un outil permettant d’émuler un système d’exploitation particulier avec un certain nombre d’applications installées. Une solution très populaire pour utiliser les conteneurs est Docker. Par rapport à une machine virtuelle, le conteneur a pour avantage de ne pas reproduire l’ensemble du système d’exploitation, en se passant du kernel. Le conteneur est donc plus léger, moins gros et plus rapide. L’inconvénient est que le conteneur ne fonctionne pas pour toutes les combinaisons de machine réelle - machine virtuelle.
Il existe d’ailleurs des outils permettant d’identifier et de capturer automatiquement un tel environnement logiciel minimum pour pouvoir le partager avec d’autres : CDE ou ReproZip. Pour en savoir plus sur Reprozip (Chirigati et al. 2016). Ces approches automatiques sont efficaces et très pratiques mais peuvent passer à côté de certaines dépendances et ne permettent pas de variation. En effet, on obtient un environnement “binaire” figé sans sa recette de construction et il est donc très difficile de changer une bibliothèque particulière ou de faire évoluer cet environnement.
16.3 Les systèmes de gestion de paquets
L’approche la plus aboutie pour la reproduction de l’environnement logiciel s’appuie sur les systèmes de gestion de paquets fonctionnels tels que :
Il s’agit d’outils permettant de décrire et d’isoler très précisément l’environnement strictement nécessaire à la recherche reproductible, de le partager avec d’autres pour qu’ils puissent le mettre en œuvre, et même d’y apporter des modifications très précisément contrôlées afin d’évaluer l’impact de tel ou tel changement.
16.4 Pour en savoir plus
Au sujet de l’identification des dépendances, vous pouvez vous référer au module 4 du MOOC sur la recherche reproductible (Inria Learning Lab 2018) et aux ressources correspondantes :
autres ressources (Legrand 2019).
Vous pouvez également vouloir regarder ce séminaire en ligne présentant quelques solutions pour contrôler son environnement (Legrand 2016a).
Références
Chirigati, Fernando, Rémi Rampin, Dennis Shasha, and Juliana Freire. 2016. “ReproZip: Computational Reproducibility with Ease.” In SIGMOD 2016 - Proceedings of the 2016 International Conference on Management of Data, 2085–8. Association for Computing Machinery. doi:10.1145/2882903.2899401.
Inria. 2017. “Guix, Un Logiciel Libre Pour La Reproductibilité Des Sciences En HPC.” Inria. https://www.inria.fr/centre/bordeaux/actualites/guix-un-logiciel-libre-pour-la-reproductibilite-des-sciences-en-hpc.
Inria Learning Lab. 2018. “MOOC « Recherche Reproductible : Principes Méthodologiques Pour Une Science Transparente »– Session 2.” Inria Learning Lab. https://learninglab.inria.fr/mooc-recherche-reproductible-principes-methodologiques-pour-une-science-transparente/.
Legrand, Arnaud. 2016a. “Controling Your Environment.” Series of Webinars and Documents on Reproducible Research. https://github.com/alegrand/RR_webinars/blob/master/2_controling_your_environment/index.org.
Legrand, Arnaud. 2019. “Bien Contrôler Son Environnement Logiciel.” Mooc Recherche Reproductible : Ressources Publiques. https://gitlab.inria.fr/learninglab/mooc-rr/mooc-rr-ressources/blob/master/module4/ressources/resources_environment_fr.org.
Lemoine, Gwenaëlle. 2017. “Packrat Ou Comment Gérer Ses Packages R Par Projet.” Bioinfo-Fr.net. https://bioinfo-fr.net/packrat-ou-comment-gerer-ses-packages-r-par-projet.
Pouzat, Christophe, Arnaud Legrand, and Konrad Hinsen. 2019. “Vers Une étude Reproductible : La Réalité Du Terrain.” Mooc Recherche Reproductible : Ressources Publiques. https://gitlab.inria.fr/learninglab/mooc-rr/mooc-rr-ressources/blob/master/module4/slides/C028AL_slides_module4-fr-gz.pdf.
Wurmus, Ricardo, Bora Uyar, Brendan Osberg, Vedran Franke, Alexander Gosdschan, Katarzyna Wreczycka, Jonathan Ronen, and Altuna Akalin. 2018. “Reproducible Genomics Analysis Pipelines with GNU Guix.” bioRxiv, April, 298653. doi:10.1101/298653.